State on the front-end
A few days ago I clicked on the thumbs-up icon on a GitHub issue, yet nothing happened. An old, dark feeling rose up again. Depression came and pointed out that I couldn’t go a day without a program malfunctioning. I hate computers. And then suddenly the number on the screen changed! I felt relieved and continued with my day.

In this post I suggest limiting such issues by simplifying state synchronization. Instead of manually fetching and saving data on a per-feature basis, I suggest treating the local state as a synced copy of the server’s database. Let me explain.
Real-time and stale data on the screen
The cause for my emotional roller coaster was simple: for a moment I lost my Wi-Fi connection, and it took a while before my HTTP request came back. Presumably the authors did not add the loading indicator because it was an insignificant feature that was not worth the effort.
Similarly, if someone else reacted while I had the page open, I would not have seen an updated reaction count until I refreshed the page. Presumably because adding real-time updates for that was not worth the effort.
Unlike reactions, however, new replies do show up in real-time, because clearly this is an important feature facilitating collaboration. There was a business case to be made and the authors added this feature.
If we continue our inspection, we’ll find that for every piece of information on the screen, the authors have decided whether it is valuable enough to add real-time updates.

In the past, the web was pure static pages and we had no expectations of real-time, we knew we needed to reload the page to see the newest data. Today, it’s halfway real-time, halfway stuck in the past.
Architecture
This real-time/stale duality is natural if we take into account how we build apps on the web. Specifically, we often handle data per application feature. For an example, with a redux-saga setup, we extract data fetching and storing into a “saga”, but every feature gets its own saga.
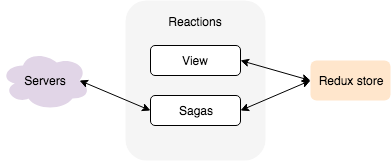
Every feature is responsible for fetching its own data: it needs to reshape the data, storing the data in the local (Redux) store, and later propagate the changes to the data back to the server.
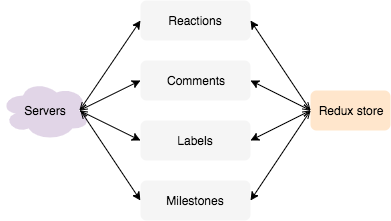
But that’s a lot of work: fetching, submitting, error handling, loading indicators and optimistic updates for every single feature. It is only natural that authors skip some of that work on the less important parts of their applications.
It doesn’t have to be this way, however. Consider, instead, if we make the store communicate with the server directly. The feature handles the view and user’s actions, and it uses the store for data. Since it’s a local store, there is no latency, no error handling, thus no extra work required.
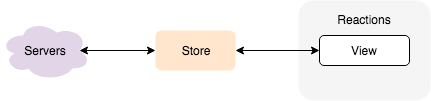
The store now needs to talk to the remote server: fetch the data, and send the changes. Consider what happens with multiple features: no matter how many features we add, our store already handles remote communication.
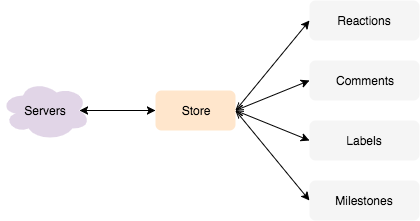
We implement fetching, submitting, error handling, loading indicators and optimistic updates only once, no matter how many features are on the screen. So for every new feature added to the screen, correct connectivity handling is free.
When an application uses this architecture, the scenario from the beginning of the article cannot happen. What happens instead is I see my click accepted, my action performed, but after a few seconds, the warning indicator will show up informing me that I am not connected. You’ve seen these messages in Gmail, Slack, and other web apps. If I try to close my tab in the meantime, a confirmation dialog shows up warning me about unsaved changes.


Tooling
This is not a complex setup fitting only big web apps. 24 lines of pure JavaScript is enough to implement such a store. This includes fetching, submitting, error handling, loading indication and optimistic updates.
const storePromise = fetch('/api/').then(res => res.json()).then(function(data) {
const changes = [];
let syncing = false;
setInterval(function() {
if (syncing) return;
syncing = true;
const currentChanges = changes.slice(0);
fetch('/api/', { method: 'PATCH', body: JSON.stringify(currentChanges) })
.then(res => res.json())
.then(function(newData) {
changes.splice(0, currentChanges.length);
data = newData;
})
.finally(() => (syncing = false));
}, 1000);
return {
everythingSaved: () => changes.length === 0,
get: function(key) {
const pending = changes.reverse().find(ch => ch.key === key);
return pending ? pending.value : data[key];
},
set: (key, value) => changes.push({ key: key, value: value }),
};
});Of course, there are already tools that are more mature than that. To find them, one needs to look for “offline-first” branding. That’s the side effect of this architecture that draws the most attention. But you don’t have to care about offline to reap design benefits. The biggest such tool is PouchDB. It provides a lot of flexibility at the cost of some learning about CouchDB. RxDB attempts to adjust PouchDB with a different API. Meteor brings an entire framework along, and Relay brings an entire syntax along. There are smaller, more focused tools, albeit with less active support: Swarm, synceddb, scuttlebot, and, perhaps the most useful at the moment, ShareDB.
Common concerns
Selecting data to sync
Once the size of user data grows, we will need to specify what to synchronize and prioritize the order of synchronization. We don’t need to sync everything to start the app, and configuring this takes some work
Conflicts
Having an explicit database synchronization does not create conflicts any more than any previous approach. Even with static pages and POST forms users have conflicts that we resolve with the “last write wins” strategy. Explicit state synchronization makes these conflicts more obvious and provides an option to resolve them better.
Maintenance of custom approaches
More popular architectures are very favorable when one needs to create a hundred identical websites and later maintain them. But if that’s the priority, I suggest Ruby on Rails or Wordpress. That said, synchronizing local data with remote data is an age-old design and cannot be called “custom”.
Back-end technology
None of the mentioned tools will function well with a regular REST API. Expect to put some effort to provide some support for these tools on the server. PouchDB relies on a CouchDB replication protocol. Meteor and ShareDB work with MongoDB. Swarm builds its own database on top of a simple storage engine.